Apache Hive简介
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
Apache Hive是使用SQL来便捷读写、管理海量分布式数据的工具。Hive可将已有数据结构化,配合命令行工具及JDBC来做分析处理。
本文讲重点介绍Hive.
数据场景
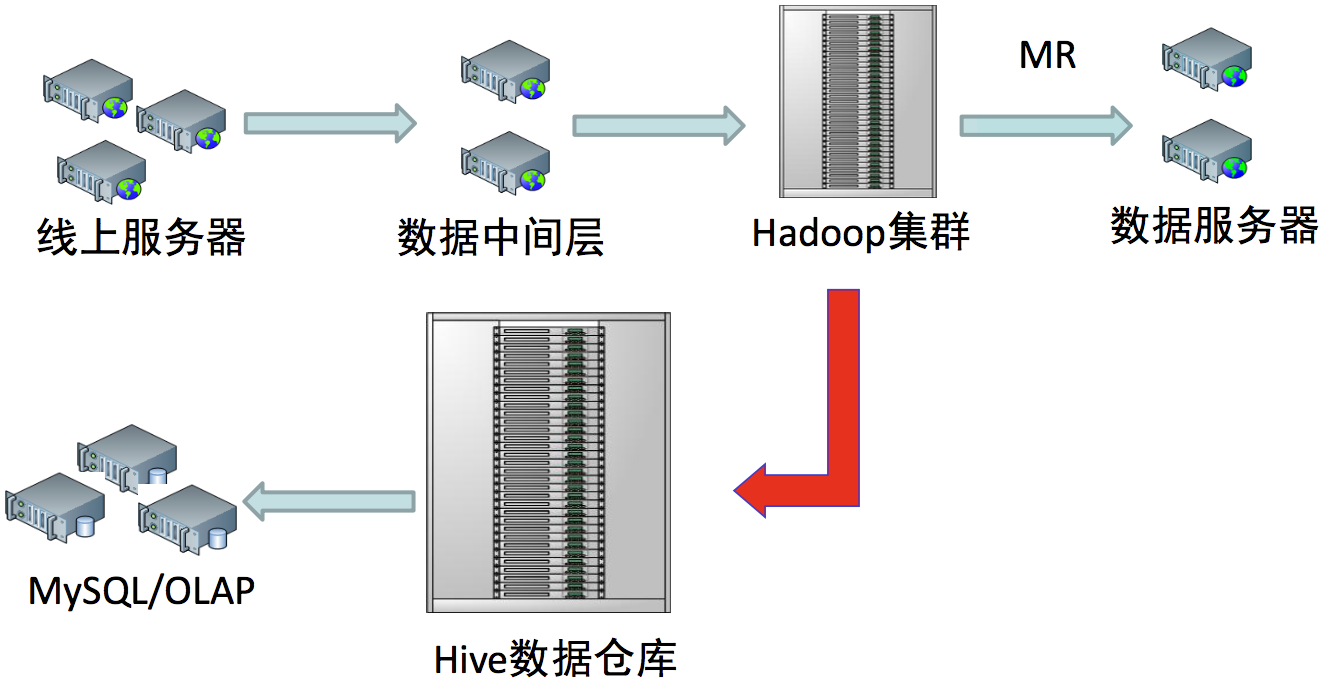
随着大数据处理、人工智能浪潮的雄起,数据愈发成为企业的核心价值所在。高效的收集、存储、分析、应用数据逐渐成为企业的竞争力所在。
线上业务一般会记录大量数据,来详细描述用户的各类行为,此类数据可能以日志、数据库、消息队列等形式体现。为方便统一处理,由数据中间层完成数据统一存储,存储至可靠的分布式文件系统。而后,由分布式计算框架(如mapreduce、spark)对数据深入的分析处理。分析过程即包含简单的统计、分析、报表等,又可包含数据挖掘、机器学习、深度学习等深入挖掘。对于统计、分析、报表类任务,起初多由MapReduce来完成,但限于研发工作量大、代码编写相对复杂、重复性工作多、缺乏统一处理等。聪明智慧的大师们,为我们带来了Hive,世界从此更加精彩。
MapReduce的局限性
- 必须使用M/R模型
- 不易重用
- 易出错
- 复杂任务支持差:
- 需写多轮MR任务
- 需编写JOIN、UNION、GROUP BY等数据库操作
- 数据schema含义难以维护
概述
Apache Hive是基于Apache Hadoop的数据仓库,使用 SQL来对分布式大数据集读写、管理,主要功能:
- 提供类SQL数据接口
- 提供ETL、数据分析、报表等数据仓库功能
- 将数据结构化的机制
- 可直接访问HDFS及Hbase上的文件
- Query可执行于Apache Tez, Spark及MR之上
数据模型
- 表(table)
- 支持操作Join,Union
- 存储于HDFS,支持外表(external tables)
- 分片(partition)
- 可以有一个或多个分片字段
- 分片决定数据的存储结构
- table location/ds=xxx
- 桶(bucket)
- 只有一个字段作为分桶依据
- 决定一个目录下有多少个文件
举个栗子:
hdfs://hdfs-prefix/path/to/wh/db_name/table_name/partition/buckets
Table:
hdfs://hdfs-prefix/wh/db/web_user_cost_day/
hdfs://hdfs-prefix/wh/db/all_web_pv_hour/
... \_ table name _/
Partition:
hdfs://hdfs-prefix/wh/db/web_user_cost_day/time_stamp=20160910/
hdfs://hdfs-prefix/wh/db/web_user_cost_day/time_stamp=20160911/
... \_ table name _/\_ partition name _/
Bucket:
hdfs://hdfs-prefix/wh/db/web_user_cost_day/time_stamp=20160910/b1
hdfs://hdfs-prefix/wh/db/web_user_cost_day/time_stamp=20160910/b2
... \_ table name _/\_ partition name _/\_bucket name_/
HiveQL
例子(word count)
DROP TABLE IF EXISTS docs;
CREATE TABLE docs(line STRING);
LOAD DATA INPATH 'input_file' OVERWRITE INTO TABLE docs;
CREATE TABLE word_counts AS
SELECT word, count(1) AS counts FROM
(SELECT explode(split(line, '\s')) AS word FROM docs) temp
GROUP BY word
ORDER BY word;
HiveQL——DDL(Hive Data Definition Language)
CREATE DATABASE/SCHEMA, TABLE, VIEW, FUNCTION, INDEX
DROP DATABASE/SCHEMA, TABLE, VIEW, INDEXTRUNCATE TABLE
ALTER DATABASE/SCHEMA, TABLE, VIEW
MSCK REPAIR TABLE (or ALTER TABLE RECOVER PARTITIONS)
SHOW DATABASES/SCHEMAS, TABLES, TBLPROPERTIES, PARTITIONS, FUNCTIONS, INDEX[ES], COLUMNS, CREATE TABLE
DESCRIBE DATABASE/SCHEMA, table_name, view_name
HiveQL——DML(Hive Data Manipulation Language)
Loading files into tables
Inserting data into Hive Tables from queries
Writing data into the filesystem from queries
Inserting values into tables from SQL
Update (hive 0.14+)
Delete (hive 0.14+)
HiveQL——DML(Hive Data Manipulation Language)
LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE]
INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
INSERT INTO TABLE tablename1 [PARTITION(partcol1=val1,partcol2=val2 ...)] select_statement1 FROM from_statement;
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...
INSERT INTO TABLE tablename [PARTITION (partcol1[=val1],partcol2[=val2] ...)] VALUES values_row [, values_row ...]
HiveQL——UDF/UDAF/UDTF
Built-in Functions
Mathematical Functions
Collection Functions
Type Conversion Functions
Date Functions
Built-in Aggregate Functions
count, sum, max, min, avg
percentile
collect_set, collect_list
Built-in Table-Generating Functions
Explode
posexplode
实现细节
HiveQL——Join
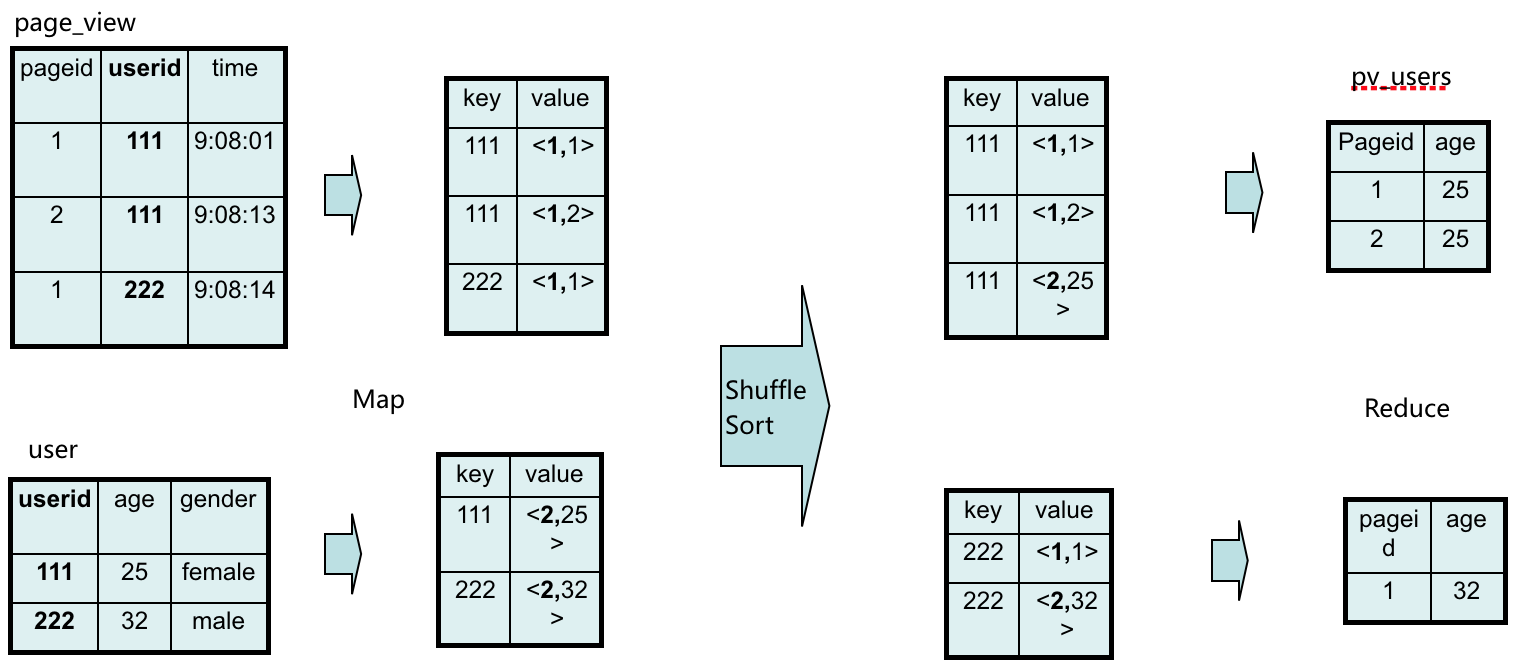
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age
FROM page_view pv
JOIN user u
ON (pv.userid = u.userid);
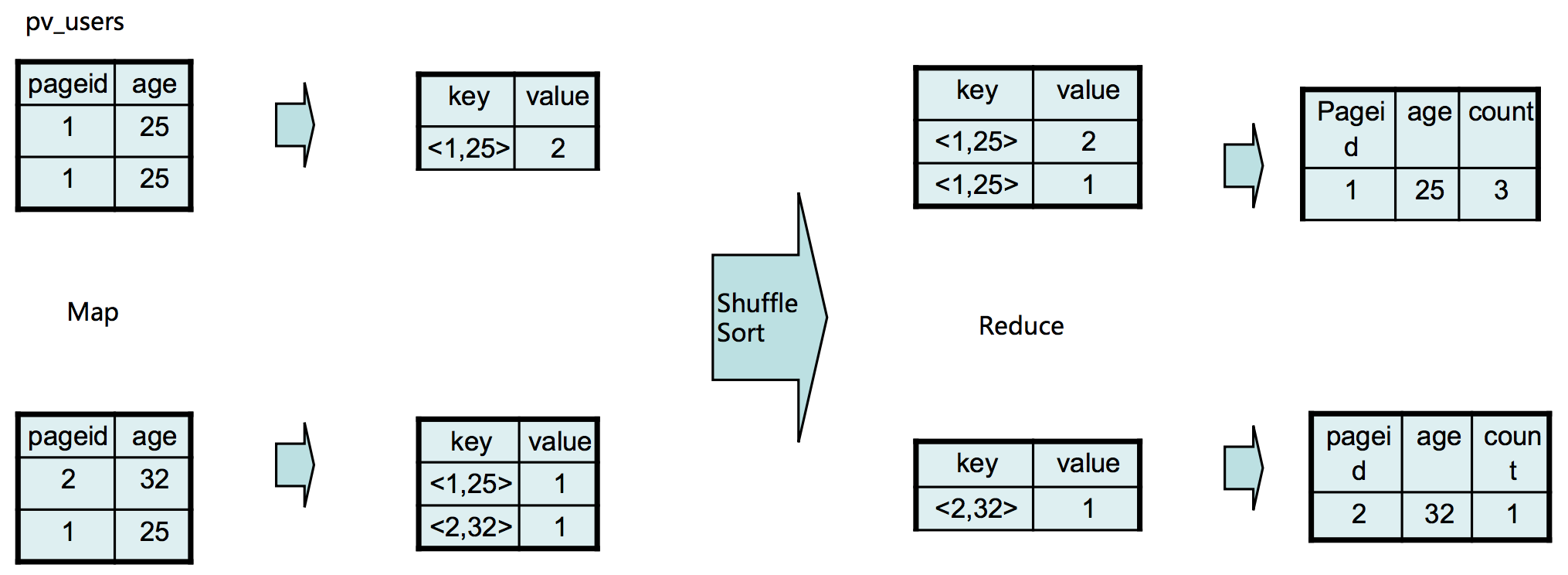
HiveQL——Group By
SELECT pageid, age, count(1)
FROM pv_users
GROUP BY pageid, age;
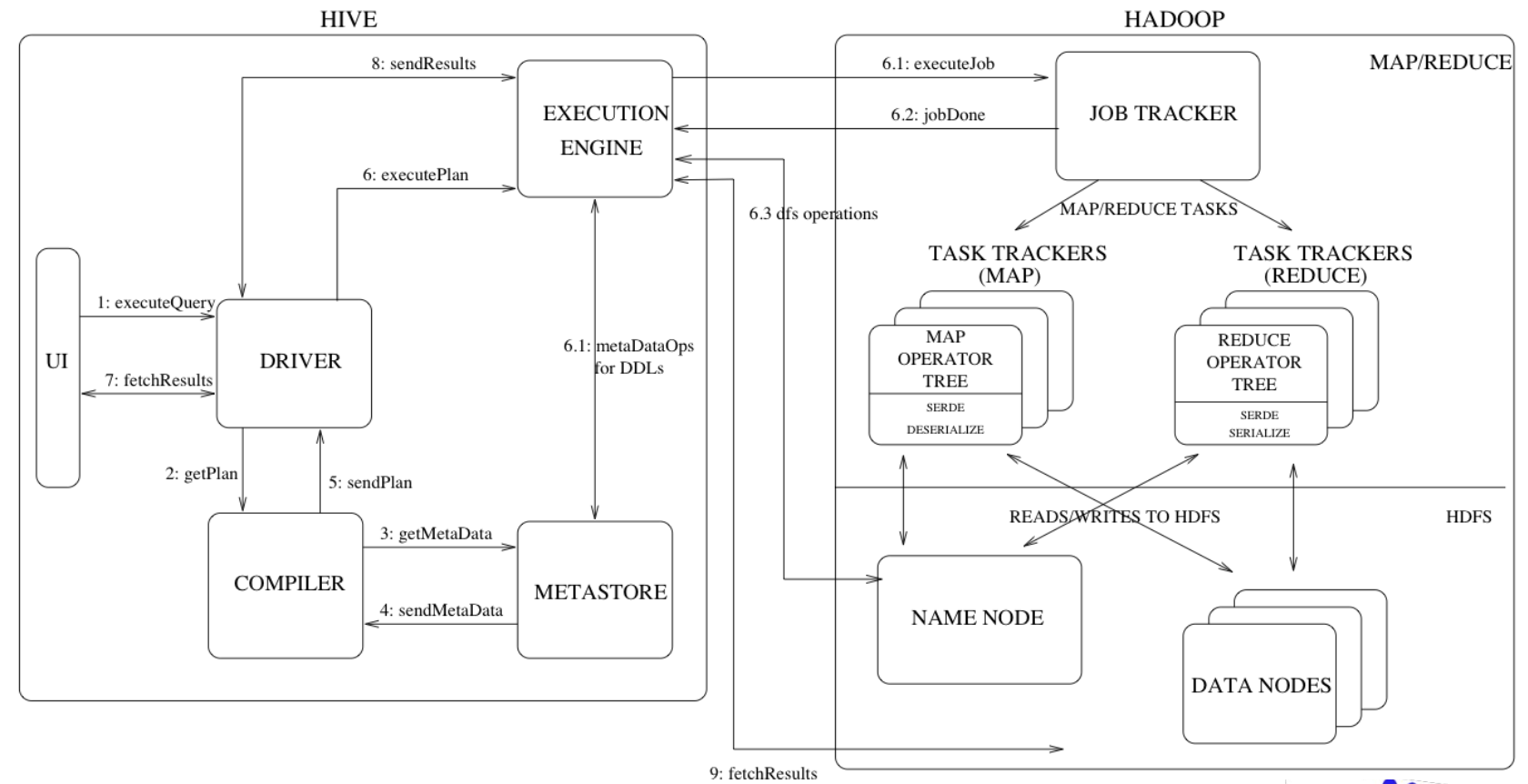
架构
架构总览
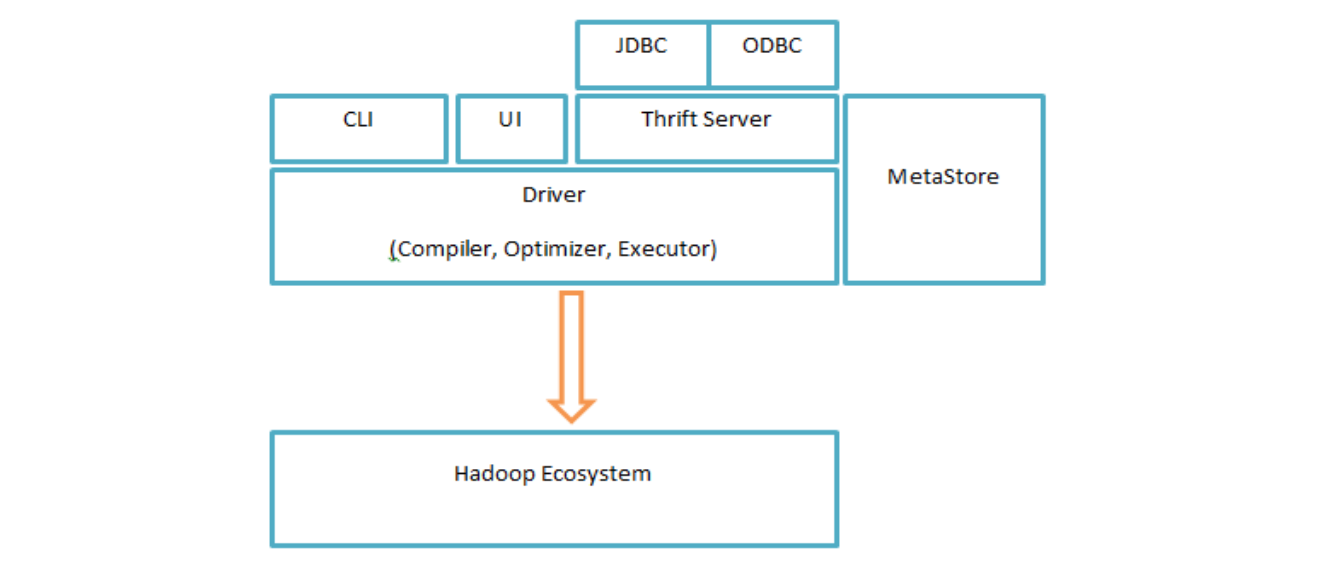
- UI: 用户接口,提交query和操作
- Driver: 接收query,处理会话
- Complier: 处理query,query语法分析
- Executor: 执行Complier生成的执行计划
- MetaStore: 存储结构化信息,字段含义、序列化信息、存储路径
详细任务流
Metastore
- 特性
- 数据抽象
- 数据检索
- Metastore 对象
- Database 对table的命名空间
- Table 表的元信息(列信息,存储、序列化)
- Partition 分片信息
- 模式
- Local/Embedded Metastore Database (Derby)
- Remote Metastore Database
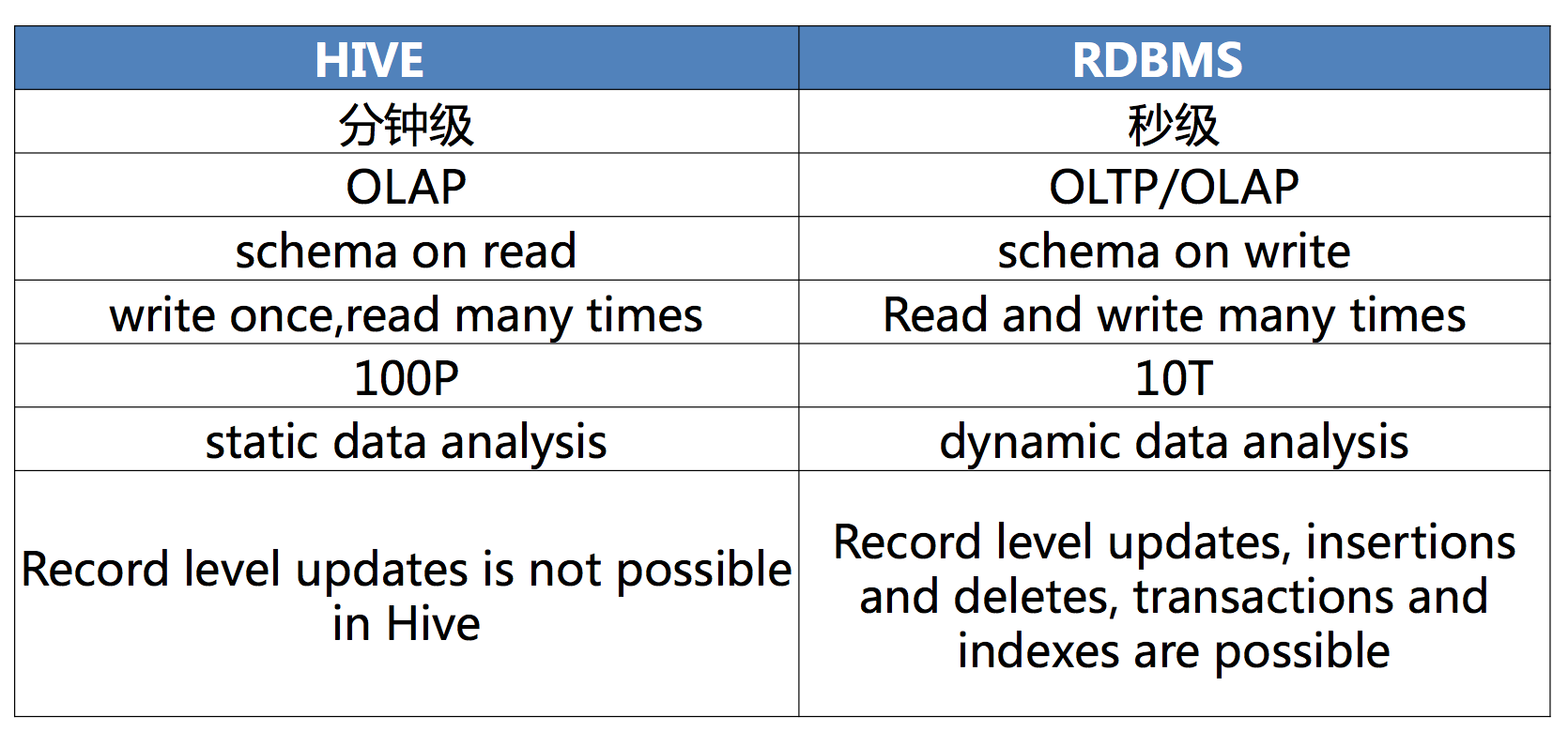
与传统数据库对比
相关项目
- Hive http://hive.apache.org/
- Hadoop http://hadoop.apache.org/
- Spark http://spark.apache.org/
- Pig http://pig.apache.org/
- Tez http://tez.apache.org/
- Hbase http://hbase.apache.org/