概述
Bigtable is a distributed storage system for managing structured data that is designed to scale to a very large size: petabytes of data across thousands of commodity servers. Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
数据模型
Bigtable是一个稀疏、多维、有序的分布式map,map由(rowkey, column, timestamp)来索引。
(row:string, column:string, time:int64) → string
Bigtable可抽象为三维Excel表格,具体来说:
- 数据可以有多行,每行由一个rowkey指定
- 一行数据可以有多列(Column),列可自由扩展
- 行列可以定位到一个Cell,Cell多版本
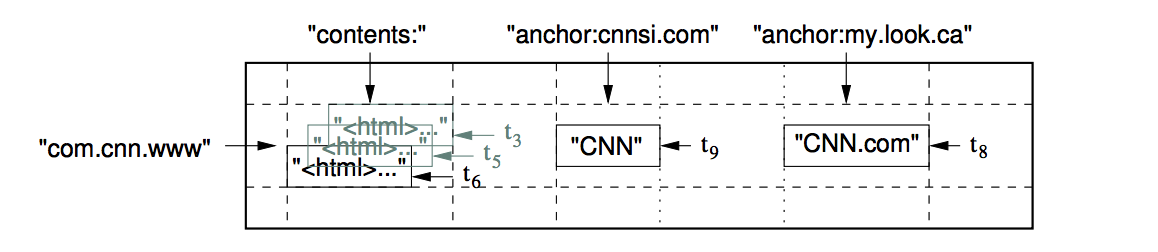
上图是论文中给出的网页库应用实例,行名是网址的逆序(保证同一站点数据集中)。列簇(column family)contents包含的源码内容,列簇anchor包含引用该网站的文本,具体来说cnnsi.com和my.look.ca均指向CNN的首页。每个anchor cell只有1个版本数据,content列的cell有3个版本数据。
逻辑视图:
{
"com.cnn.www" : {
contents: {
t6: contents:html: "<html>..."
t5: contents:html: "<html>..."
t3: contents:html: "<html>..."
},
anchor: {
t9: anchor:cnnsi.com = "CNN"
t8: anchor:my.look.ca = "CNN.com"
}
}
}
Raws
Rowkey是一个二进制串,Bigtable里的数据按照rowkey的字典序排列, 同时按照rowkey的区间将数据动态分区,每个分区称为一个tablet.数据按rowkey排列,并做range分区,数据按区间scan会非常快,譬如获取某host下所有网页,只需指明起止区间即可快速获取.
Column/Column family
Column组织为一个Column family, column family需在建表时指明,column可按需来建立,column必须属于某一column family;column family下可有任意数量的column,数据的存储和读取上都是按照column family来组织的,故使用相关度高的column应组织在相同的column family下.
Timestamps
Bigtable的Cell均支持多版本,版本由timestamp来指明,timestamp可由bigtable来指明(系统时间),也可由应用本身来指明,对数据冲突敏感的应用最好自己来管理版本,毕竟分布式系统中的时间不是可靠的。Bigtable提供基于版本的GC策略,策略为column falmily粒度,有两类:1. 指明数据的TTL,超过TTL数据被GC;2. 指明数据保留版本数量(最多保存多少版本,最少保存多少版本),实际场景中该GC策略极其有用。
Data Model Operations / API
Hbase shell command
Put
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds
Get
hbase(main):007:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1421762485768, value=value1
1 row(s) in 0.0350 seconds
Scan
hbase(main):006:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1421762485768, value=value1
row2 column=cf:b, timestamp=1421762491785, value=value2
row3 column=cf:c, timestamp=1421762496210, value=value3
3 row(s) in 0.0230 seconds
API
TODO
Implementation / Architecture
The Bigtable implementation has three major components:
- a library that is linked into every client
- one master server.
- many tablet servers.
Master server:分派tablet到tablet server,探测tablet server状态,做负载均衡,依据需要添加/剔除tablet server. Table、column family的schema也由Master server来管理。
Tablet server: 管理一批tablet,对应tablet的读写通过tablet server来完成,数据读写直接由client与tablet server来交互,大tablet的split也是由tablet server来完成的。
Tablet Location
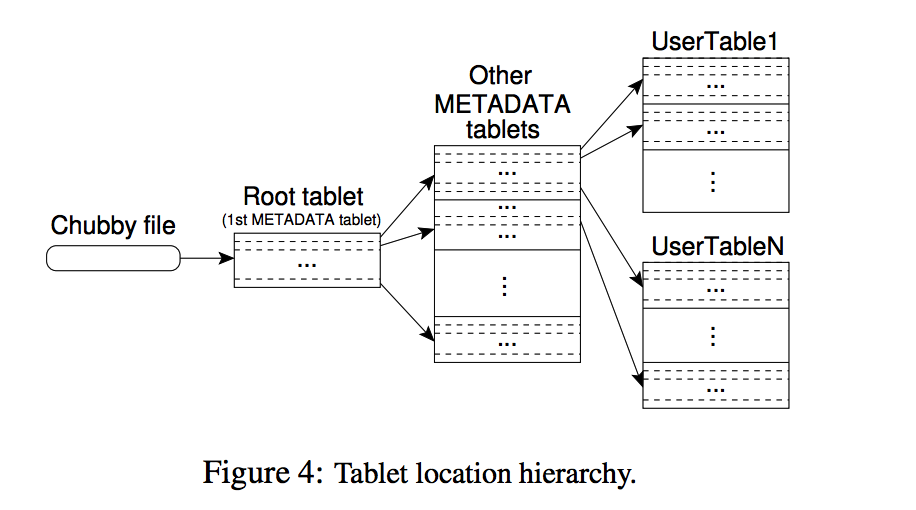
Tablet Assignment
- Chubby's role
- Master on start
- Tablet server Failover
Tablet Serving
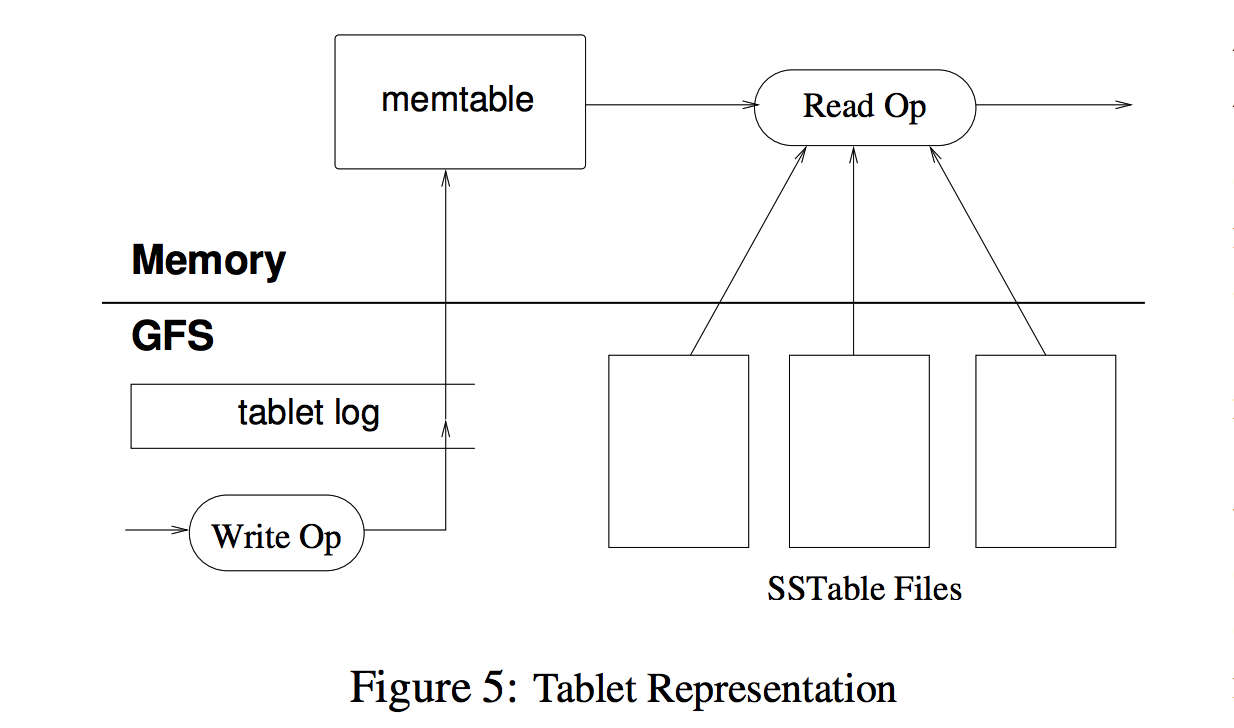
- memtable
- SSTable
- LSM-tree
Compactions
- minor compaction
- major compaction
Features calls for
- secondary indices
- cross-data-center replicated Bigtables
References
- BigTable (Bigtable: A Distributed Storage System for Structured Data Google, Inc.)
- Hbase data model
- Hbase http://hbase.apache.org/
- Hadoop http://hadoop.apache.org/